
TL;DR:
- Effective product recommendations are crucial for increasing e-commerce sales, as they can generate up to 35% of revenue and improve conversion rates significantly. Combining behavioral, product-related, and contextual data at scale through a two-stage architecture enhances relevance and accuracy, with hybrid systems outperforming single-method approaches. Prioritizing purchase history, browsing behavior, and product attributes, while incorporating human and AI-driven curation, builds trust and boosts overall revenue.
Every e-commerce marketing manager has seen it: a shopper browses a $200 camera, and your site recommends a $15 phone case with zero relevance. They leave frustrated, and you leave money on the table. Getting product recommendations right is one of the highest-leverage moves in e-commerce, and the brands doing it best are not guessing. Amazon credits 35% of its revenue to its recommendation engine, with typical sales lifts running between 10% and 35%. This article breaks down the data types, system architectures, proven benchmarks, and expert strategies you need to turn your recommendation engine into a serious revenue driver.
Table of Contents
- Understand the key types of product recommendations data
- How modern product recommendation systems use your data
- What works (and what doesn’t): Lessons from large-scale benchmarks
- Expert insights: Maximizing trust and relevance with your recommendations
- Our perspective: Why data isn’t enough—empathy and context rule
- Leverage advanced analytics for better product recommendations
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Leverage multi-source data | Combining behavioral, product, and contextual data yields more relevant recommendations and higher conversions. |
| Use two-stage systems | Retrieval plus rich ranking consistently outperforms single-shot or single-data-type approaches at scale. |
| Match price bands | Recommending products in similar price ranges maintains conversion rates and boosts overall sales. |
| Prioritize hybrid methods | Hybrid recommendation engines show 15–25% better sales lift than isolated techniques. |
| Focus on trust and context | Balancing automated data use with brand empathy and timing is key to building customer trust and loyalty. |
Understand the key types of product recommendations data
Before you can build smarter recommendations, you need to be clear on what raw material actually powers them. Most teams start with whatever data they already collect, but the highest-performing systems are deliberate about combining several distinct categories.
Behavioral data is your richest signal. It includes browsing history, product clicks, time spent on pages, add-to-cart actions, wish lists, and completed purchases. When a customer spends three minutes on a hiking boot product page but does not buy, that hesitation is data. When they return two days later and buy, that path is data. Every touchpoint tells you something about intent.
Product-related data covers the attributes of each item in your catalog: category, price, margin, inventory status, tags, and even product descriptions. This layer matters more than people realize. Recommending an item that is out of stock or priced wildly outside the shopper’s established range actively hurts conversion rates. Guardrails built on product data prevent these costly mistakes.
Contextual data adds the situational layer: what device the shopper is using, what time of day it is, their location, and even the weather. A mobile shopper at 10 PM behaves differently than a desktop shopper at 2 PM on a Tuesday. Systems that ignore context leave significant uplift untapped.
Real-world leaders like Amazon do not just use one category. Their systems leverage embedding models (which capture product similarity), co-buy signals (products frequently purchased together), and ranking features like margin scores and category affinities, all applied at different stages of the recommendation pipeline. That combination is why their results are so consistently strong. If you want to explore smart recommendation ideas for your own store, the frameworks used by large-scale systems translate directly to mid-market brands with the right toolset.
“Guardrails on price, stock, and diversity are not optional features in large-scale recommendation systems. They are the difference between a system that helps and one that harms.”
Pro Tip: Do not limit yourself to basic clickstream data. Enriching each session event with contextual parameters like device type, local time, and session depth gives your models far more signal to rank on. Even a simple CSV export from your order management system contains far more behavioral patterns than most teams ever analyze. You can review the glossary of recommendation terms to get a clear handle on the vocabulary before diving into system architecture.
Key data types every recommendation system should use:
- Purchase history: The strongest signal for co-purchase and basket analysis
- Browsing and click behavior: Captures latent intent before a purchase decision
- Product catalog attributes: Price, category, margin, inventory, and tags
- Session context: Device, time, location, and visit frequency
- Real-time cart data: What is currently in the session basket influences what to suggest next
How modern product recommendation systems use your data
With a solid grasp on your data sources, it is crucial to see how modern systems process and apply them for real business value. The architecture is less mysterious than it sounds, and understanding it helps you make better decisions about where to invest.

Modern recommendation systems at scale follow what is called a two-stage architecture: a fast candidate retrieval phase followed by a precise ranking phase. This design is not arbitrary. You cannot run a computationally expensive ranking model across your entire catalog for every shopper in real time. So the first stage quickly narrows thousands of products down to a manageable candidate set, typically a few hundred items. The second stage then applies richer, more expensive features to rank those candidates precisely.
Here is how data flows through a typical modern recommendation system:
- Trigger event: A shopper views a product or adds an item to cart
- Candidate retrieval: Embedding models and co-purchase signals pull 100-300 relevant candidates from the catalog fast
- Feature enrichment: Each candidate gets scored on affinity, price compatibility, margin, and inventory status
- Ranking: A ranking model orders the candidates by predicted conversion probability
- Guardrail filtering: Out-of-stock items, wildly mispriced products, and duplicates are removed
- Delivery: The top 4-8 recommendations are served to the shopper in real time
| Stage | Data types used | Speed priority | Accuracy priority |
|---|---|---|---|
| Candidate retrieval | Embeddings, co-buy signals, category match | Very high | Moderate |
| Ranking | Affinities, price score, margin, context | Moderate | Very high |
| Guardrail filtering | Inventory, price band, diversity rules | High | High |
The payoff for this ecommerce recommendation guide approach is significant. Hybrid systems that combine multiple data types and algorithms outperform single-method systems by 15% to 25% in sales uplift. Single-method systems, like those relying only on collaborative filtering or only on category matching, leave a meaningful gap. Mixing behavioral data with product attributes and contextual signals is where the real gains live.
Pro Tip: Build price-band and inventory guardrails into your ranking stage, not as an afterthought. A recommendation that points to an out-of-stock item or a product priced four times higher than what the shopper is considering will actively reduce trust and session value. Review your AI optimization checklist to make sure these guardrails are in place before you scale.
What works (and what doesn’t): Lessons from large-scale benchmarks
Now that we have seen the technical side, let us look at real-world data for what actually drives results and what to avoid. Benchmarks are more instructive than theory because they expose the failure modes that pure architecture discussions miss.
The headline number is well-known: Amazon attributes roughly 35% of revenue directly to its recommendation engine. Across e-commerce benchmarks more broadly, personalized recommendations produce conversion lifts of 10% to 35% and average order value increases of 20% to 40%. These are not incremental improvements. They represent a compounding advantage that widens over time as models learn from more data.
| Approach | Typical sales uplift | AOV impact | Implementation complexity |
|---|---|---|---|
| Single-method (category only) | 5-8% | Low | Low |
| Collaborative filtering alone | 8-12% | Moderate | Moderate |
| Hybrid (behavioral + product + context) | 15-25%+ | High | Moderate-High |
| Amazon-style multi-stage hybrid | Up to 35% | Very high | High |
One of the most actionable findings from recent research involves price compatibility. Most teams focus on relevance and category match but overlook price band alignment. The data is stark: recommending differently priced products reduces purchase probability by 21%, particularly for related items where the shopper expects price parity. On the positive side, matching price bands delivers a 4% total sales gain across the recommendation surface. That is a meaningful lift just from one constraint.
“A 21% drop in purchase probability occurs when shoppers are shown related products at significantly different price points. Price compatibility is not a nice-to-have. It is a conversion requirement.”
Common pitfalls that benchmarks consistently surface:
- Ignoring price bands: Recommending a $300 accessory alongside a $30 main product confuses shoppers and reduces purchase intent
- Showing out-of-stock items: Even a single irrelevant recommendation erodes session trust
- Over-recommending from the same category: Diversity in the recommendation set increases basket size more than doubling down on one category
- Relying on popularity alone: Best-sellers lists recommend what sold yesterday, not what this specific shopper needs today
- Static recommendations: Systems that do not update based on real-time cart composition miss upsell windows
For a deeper look at the revenue mechanics, the cross-selling best practices framework and the broader landscape of AI applications for ecommerce provide concrete playbooks for putting these benchmarks to work.
Expert insights: Maximizing trust and relevance with your recommendations
Understanding the mechanics and pitfalls sets the stage for integrating expert strategies that boost both trust and purchase likelihood. The technical architecture gets you most of the way there, but the final mile is about human behavior.
Price band matching is the single most underused lever in recommendation optimization. When a shopper is considering a $150 item, recommendations in the $120 to $180 range feel natural and relevant. Recommendations at $50 feel like a downgrade. Recommendations at $400 feel presumptuous. Implementing price-band matching in your ranking stage is one of the fastest wins available to any e-commerce team.
Context-aware filtering is the second lever most teams underuse. Device type matters: mobile shoppers convert on fewer, simpler recommendations, while desktop shoppers engage with richer product carousels. Time of day matters: evening shoppers often browse aspirationally and respond to discovery-style recommendations, while lunchtime shoppers are more likely in task completion mode and want functional cross-sells. Your automated retail analytics setup should be capturing these signals and feeding them into your ranking model.
How human curation and machine-generated recommendations build trust differently:
- Machine recommendations drive functional trust: shoppers believe the system has processed more data than any human could and will surface the most relevant options
- Human curation drives social trust: editorial picks, stylist selections, and “staff favorites” feel personally endorsed and authentic
- Combined approaches build both trust types simultaneously, with editorial curation feeding into algorithmic models as a training signal
- Timing matters for trust: Human curation works especially well for new products with limited behavioral data; algorithms take over as data accumulates
- Transparency increases trust: Labeling a recommendation “Because you bought X” or “Trending in your size” gives shoppers a reason to believe it
Pro Tip: Run a parallel A/B test with pure algorithmic recommendations on one variant and a hybrid editorial-plus-algorithmic approach on the other. The results often surprise teams. For specific categories like fashion or home decor, editorial curation can outperform pure algorithms by double-digit margins, while electronics and consumables tend to favor algorithmic approaches. Your AI sales optimization strategies should account for category-level differences, not just site-wide averages.
Our perspective: Why data isn’t enough—empathy and context rule
Here is the uncomfortable truth most recommendation vendors will not tell you: a technically perfect recommendation system can still produce results that feel cold, obvious, or even off-putting to your customers. We have seen brands implement two-stage architectures with robust hybrid models and still underperform because they treated recommendation optimization as a purely technical problem.
The brands that consistently win are the ones that pair strong data infrastructure with a genuine understanding of why their customers buy. A running shoe brand that understands its customers are buying confidence, not just footwear, recommends recovery products and training accessories because those items speak to the same emotional driver. A technically trained model that only looks at co-purchase signals might recommend a second pair of shoes because the correlation is high in the data. That is technically correct and commercially mediocre.
Over-personalization is a real risk that benchmarks rarely capture. When every interaction feels algorithmically predicted, some shoppers feel surveilled rather than served. There is a point where recommendation accuracy tips from “this feels helpful” to “this feels like the site knows too much about me.” The brands navigating this well are the ones that build recommendation experiences with intentional breathing room and brand voice, not just maximum precision.
Testing on your actual customers beats relying on published benchmarks. Amazon’s 35% revenue figure is real, but it was built over two decades on a specific customer base with specific buying patterns. Your customers are not Amazon’s customers. Multi-variant tests on your own transaction data will tell you more about your specific recommendation opportunities than any industry study. The foundation for that kind of analysis starts with understanding your transaction data at the product association and customer segment level.
“The best recommendation systems delight not just because they are accurate, but because they feel relevant, timely, and human.”
Leverage advanced analytics for better product recommendations
The strategies and benchmarks covered in this article require solid data infrastructure and the ability to analyze patterns in your transaction history without needing a data science team on staff.
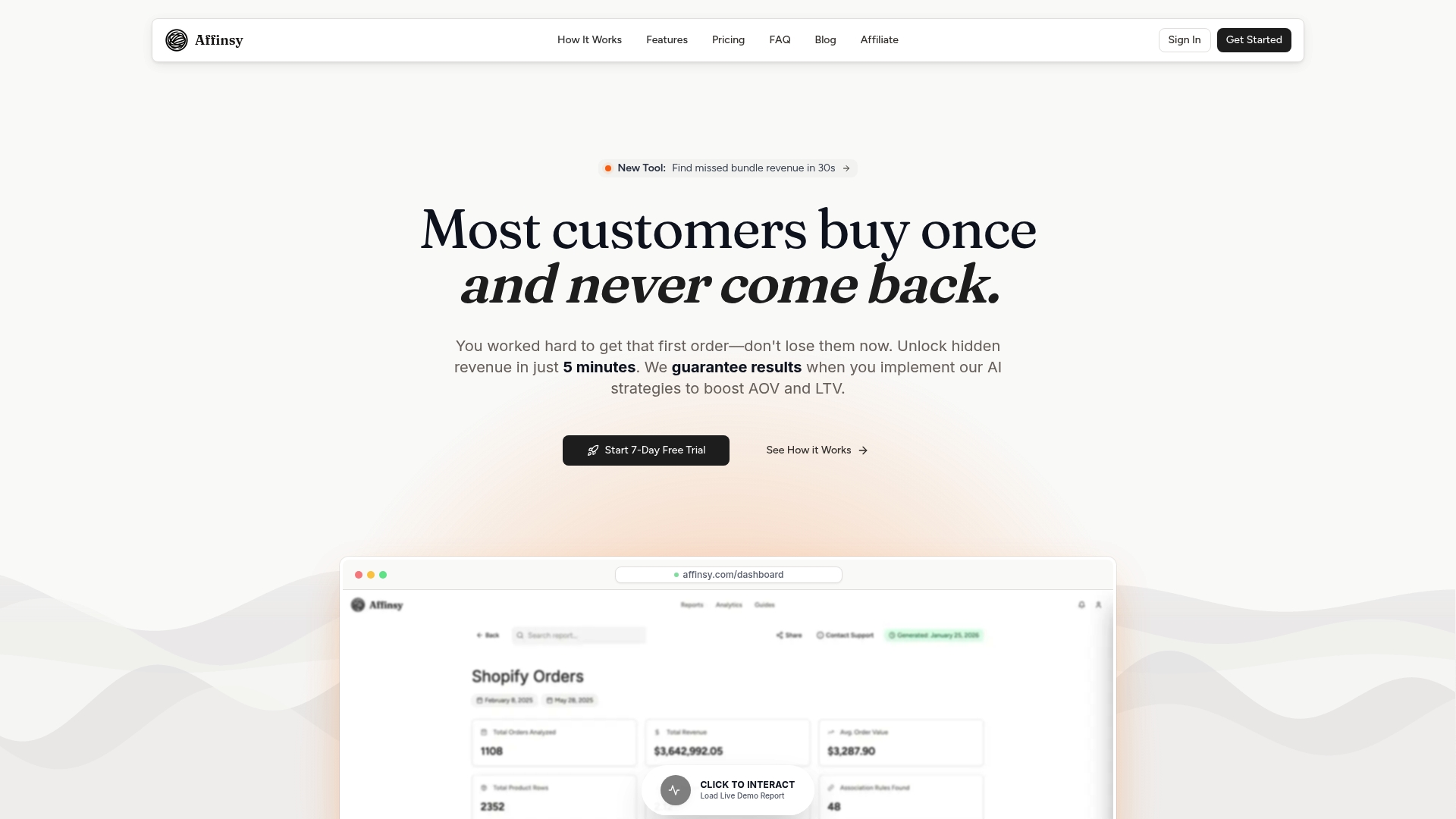
Affinsy makes that analysis accessible for mid-to-large e-commerce brands. By running market basket analysis on your historical order data, you can surface the real co-purchase associations that drive your specific customer base. Pair that with customer segmentation based on RFM patterns, and you get a clear picture of which products to recommend to which customers at which stage of their lifecycle. If you are running WooCommerce, our free WooCommerce order exporter gets your data into Affinsy in minutes. The permanent free tier covers up to 20K line items with no credit card required, so you can start finding patterns in your data today.
Frequently asked questions
How do product recommendations affect e-commerce sales?
They can drive 10-35% more sales and boost average order values by up to 40%, with Amazon’s recommendation engine alone accounting for 35% of its total revenue.
Is recommending higher- or lower-priced products better for conversions?
Recommending items in a similar price range consistently outperforms both directions. Recommending differently priced products reduces purchase probability by 21%, while price-matched recommendations produce a 4% total sales gain.
What’s a two-stage recommendation architecture?
It is a system that first quickly retrieves a broad set of candidate products, then applies richer data features to rank them precisely. This two-stage approach is standard for large-scale e-commerce because it balances speed with accuracy.
Can human curation beat automated recommendations?
Both have distinct strengths: human editorial picks build social trust and work especially well for new products, while algorithms excel at personalization at scale. Human vs. machine recommendations differ primarily in their trust mechanisms, one functional and one social.
What data should I prioritize first for recommendations?
Start with purchase history and browsing behavior since these carry the strongest intent signals, then layer in product attributes like price and category, and finally add contextual data for the biggest cumulative impact.
Recommended
- Smarter Sells Product Recommendations Ecommerce Guide - Affinsy Blog | Affinsy
- 7 Smart Product Recommendation Ideas for E-Commerce Growth - Affinsy Blog | Affinsy
- How to Improve Cross-Selling With Data-Driven Strategies - Affinsy Blog | Affinsy
- Proven cross-selling tips to boost e-commerce sales in 2026 - Affinsy Blog | Affinsy