
TL;DR:
- Automated transaction analytics uses software pipelines to process and analyze transaction data with minimal human input, significantly reducing errors and saving time for finance teams. Building an effective system involves four key layers: data ingestion, normalization, AI-powered matching, and exception routing, which must work seamlessly together. Incorporating AI enhances accuracy over time, enables continuous monitoring, and transforms raw data into strategic insights for e-commerce growth.
Automated transaction analytics is the practice of using software pipelines to ingest, normalize, match, and analyze transaction data with minimal human intervention. Finance teams that adopt this approach reduce manual errors by ~90% and save over 40 hours of administrative work every month. For e-commerce professionals managing thousands of daily orders across Stripe, PayPal, and Square, knowing how to automate transaction analytics is no longer optional. It is the difference between reacting to problems and preventing them.
How to automate transaction analytics: core components
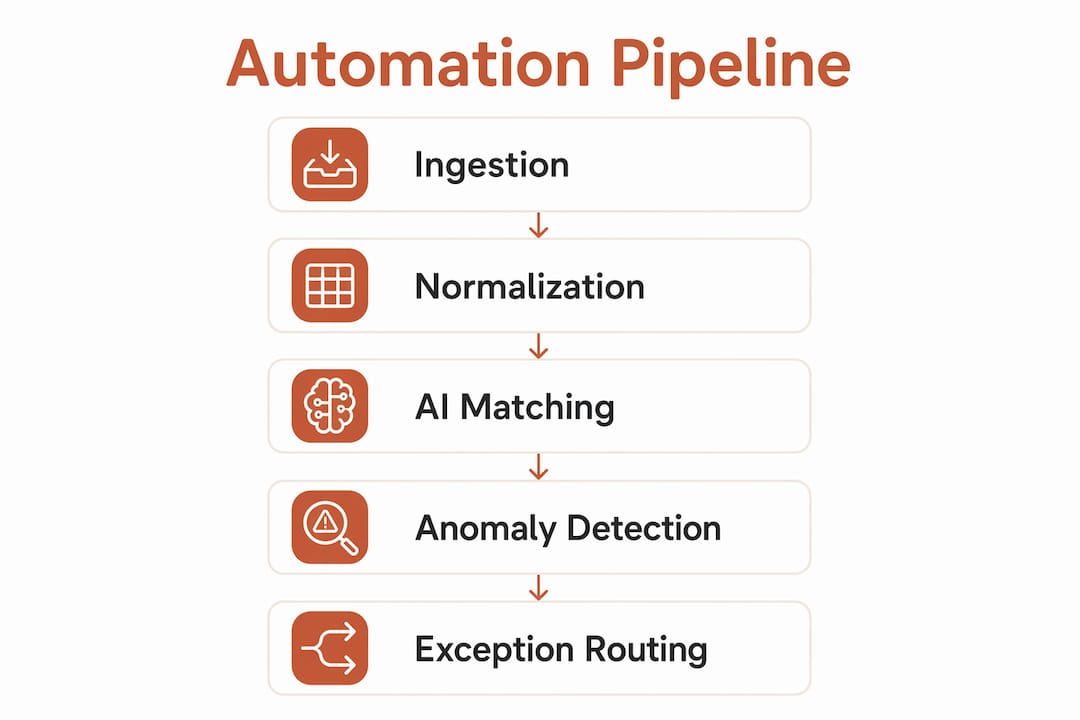
Building an automated transaction analytics pipeline requires four distinct layers working together. Skip any one of them and the whole system breaks down.
The first layer is data ingestion. Your pipeline must pull transaction records from every payment processor you use. Stripe, PayPal, Square, and ACH transfers each produce data in different formats and at different intervals. A multi-source ingestion layer that unifies payment sources into a single ledger is the foundation of any working automation setup.
The second layer is normalization. Raw transaction data from multiple processors contains inconsistent date formats, currency codes, and reference IDs. Data format discrepancies are the leading cause of failed automated matches. A normalization layer converts everything into a canonical schema before any matching or analysis begins.
The third layer is AI-powered matching and reconciliation. Platforms like Embat and Optimus use fuzzy logic and machine learning to match transactions across sources without requiring exact string matches. The fourth layer is exception routing, which flags unresolved records for human review instead of letting them stall the entire pipeline.
Here is how major tools compare across these layers:
| Tool | Ingestion | AI Matching | Anomaly Detection | Exception Routing |
|---|---|---|---|---|
| Embat | API, CSV | Yes | Yes | Yes |
| Optimus | API | Yes | Yes | Yes |
| NAYA | API | Fuzzy logic | Yes | Yes |
| Open-source (Python + Plaid) | API, CSV | Rule-based | Basic | Manual |
How to build an automated analytics workflow step by step
A structured five-step process covers everything from raw data ingestion to finished reports. Follow this sequence and you avoid the most common implementation failures.
-
Connect and ingest transaction data. Pull records from all payment processors via API or scheduled CSV exports. Stripe and PayPal both offer webhook-based event streams that push data in real time. Square and ACH sources typically require polling. The goal is a single raw data store that captures every transaction regardless of source.
-
Normalize into a canonical schema. Convert all timestamps to UTC, standardize currency codes to ISO 4217, and assign a universal transaction ID to every record. The normalization layer handles currency conversion, timestamp alignment, and reference ID standardization. This step alone eliminates the majority of false negatives in downstream matching.
-
Apply AI-powered fuzzy matching for reconciliation. Use a confidence scoring system to categorize matches. Records scoring above 85% confidence get auto-approved. Records scoring between 50% and 85% go to a review queue. Tiered confidence scoring reduces both false negatives and unnecessary manual workload at the same time.
-
Detect anomalies and route exceptions. Run statistical checks against historical baselines to flag unusual transaction volumes, duplicate charges, or unexpected refund spikes. Route flagged records to the appropriate team member via email or a tool like Slack. Platforms like Anomalo do this autonomously, sending natural language anomaly explanations directly to the people who need to act on them.
-
Generate automated reports and insights. Schedule daily or weekly summary reports that pull from your normalized, matched dataset. Connect this output to your business intelligence layer for dashboards that update without manual input.
Pro Tip: Set your auto-approval threshold conservatively at first, around 90% confidence, then lower it gradually as your matching model learns from historical corrections. Starting too low creates a flood of exceptions that discourages the team from trusting the system.
What are the biggest challenges in transaction analytics automation?
Most automation projects stall at the same three points: data inconsistency, threshold misconfiguration, and metric fragmentation. Knowing where these failures happen lets you prevent them before they cost you weeks of rework.
Data inconsistency is the most common root cause of poor automation performance. Payment processors do not agree on field names, date formats, or ID structures. A transaction labeled “order_id” in Stripe becomes “reference_number” in PayPal. Without a normalization step that resolves these differences before matching, your automation rates stay low regardless of how good your matching algorithm is.
Threshold misconfiguration creates two opposite problems. Set your auto-approval threshold too high and you flood reviewers with exceptions. Set it too low and you approve incorrect matches automatically. The right balance depends on your transaction volume and error tolerance. Firms that reach 90%+ automation rates typically spend the first 60 days tuning thresholds against real data before scaling.
Metric fragmentation happens when different teams define the same metric differently. Revenue in the marketing dashboard does not match revenue in the finance report because each team built their own calculation. A central semantic layer that defines business logic once and applies it everywhere prevents this problem entirely.
Automation does not eliminate the need for human judgment. It concentrates human attention where it matters most: on the exceptions that a machine cannot confidently resolve.
Pro Tip: Build a “known exceptions” catalog from your first 30 days of operation. These are recurring mismatches that your system flags repeatedly but that always resolve the same way. Codifying them as rules eliminates a large share of manual review work permanently.
Here are the most common pitfalls and how to address them:
- False negatives from unnormalized IDs: Standardize all reference IDs in the normalization layer before matching begins.
- Duplicate transaction records: Add a deduplication check using composite keys (amount + timestamp + processor ID) before ingestion completes.
- Stale exception queues: Set SLA alerts that escalate unresolved exceptions after 24 hours.
- Conflicting metric definitions: Implement a semantic layer using a tool like Cube to enforce consistent business logic across all reports.
- Model drift over time: Schedule monthly reviews of your matching model’s accuracy against a labeled validation set.
How does AI improve transaction analytics automation?
AI moves transaction analytics from a scheduled batch process to a continuous, self-improving system. That shift has real operational consequences. Automated reconciliation now enables continuous month-end closing, cutting the average close cycle by 5 days compared to traditional 10-day batch processes.

The most significant AI contribution is autonomous anomaly detection. Rather than waiting for a human analyst to notice a spike in chargebacks or a drop in settlement amounts, AI agents monitor transactions in real time and push root-cause explanations to the right person before the issue compounds. This is the shift from reactive dashboards to proactive intelligence that defines modern e-commerce analytics.
Pattern-learning agents add a second layer of value. AI-powered categorization automates roughly 60% of manual coding tasks, freeing analysts to focus on the 40% that requires business judgment. These agents also improve over time. As reviewers correct mismatches, the model updates its matching rules automatically, which means your automation rate increases the longer the system runs.
Here is how manual and AI-enhanced workflows compare in practice:
| Dimension | Manual Workflow | AI-Enhanced Workflow |
|---|---|---|
| Reconciliation speed | 10-day batch cycle | Continuous, near real-time |
| Error rate | High, spreadsheet-dependent | ~90% reduction |
| Anomaly detection | Reactive, post-close | Proactive, real-time alerts |
| Coding automation | 0% | ~60% of tasks automated |
| Human role | Data entry and matching | Exception review and strategy |
For e-commerce teams, the practical implication is clear. AI workflow tools in 2026 handle multi-source ingestion, advanced anomaly detection, and exception routing at a speed and accuracy level that manual processes cannot approach.
How to connect transaction automation to e-commerce strategy
Automated transaction data becomes a strategic asset when you feed it into the right analytical models. The output of your reconciliation pipeline is not just clean financial records. It is a structured dataset that powers customer segmentation, product bundling decisions, and fraud prevention.
Here is how to connect automation outputs to broader e-commerce strategy:
- Market basket analysis: Feed normalized transaction records into an MBA model to identify which products customers buy together. This directly informs cross-sell recommendations and bundle pricing. Affinsy analyzes historical transaction data to surface these associations without requiring data science skills.
- RFM customer segmentation: Use transaction frequency, recency, and monetary value from your automated pipeline to segment customers dynamically. Segments update automatically as new transactions flow in, keeping your marketing lists current. You can learn more about applying this through transaction data analysis for e-commerce growth.
- Dynamic pricing and promotion optimization: Continuous transaction monitoring reveals which products see demand spikes at specific times. That data feeds directly into promotion scheduling and price adjustment logic.
- Fraud prevention: Anomaly detection flags that your reconciliation pipeline generates are the same signals your fraud team needs. Route high-risk transaction flags to your fraud review queue automatically rather than treating them as separate workflows.
- Company-wide reporting consistency: Connect your normalized transaction data to a semantic layer so that every team, from marketing to finance, pulls from the same source of truth. This is the foundation of trusted automated reporting across complex e-commerce operations.
The teams that get the most value from transaction automation are the ones who treat clean transaction data as an input to every business decision, not just a reconciliation output. For a broader view of how automation drives e-commerce growth, the connection between reconciliation pipelines and strategic analytics is where the real gains appear.
Key takeaways
Automating transaction analytics requires a five-layer pipeline covering ingestion, normalization, AI matching, anomaly detection, and semantic reporting to deliver reliable, scalable insights.
| Point | Details |
|---|---|
| Normalization comes first | Standardize date formats, currencies, and IDs before any matching begins to prevent false negatives. |
| Use tiered confidence scoring | Auto-approve matches above 85% confidence and route 50–85% scores to human review. |
| AI cuts manual coding by ~60% | Pattern-learning agents automate categorization tasks, freeing analysts for high-judgment exceptions. |
| Semantic layer prevents metric drift | A central business logic layer keeps revenue and KPI definitions consistent across all teams. |
| Connect outputs to strategy | Feed clean transaction data into MBA and RFM models to drive cross-sell, segmentation, and fraud prevention. |
The part most teams get wrong
Most e-commerce teams I have worked with treat transaction automation as a finance project. They hand it to the accounting team, declare success when reconciliation runs without errors, and never connect the output to marketing, product, or growth decisions. That is the wrong frame entirely.
The real value of automating transaction analytics is not error reduction, though saving 40 hours a month is genuinely useful. The value is the structured, normalized, continuously updated dataset you now have access to. That dataset is the raw material for every meaningful e-commerce insight: which products drive repeat purchases, which customer segments are churning, which promotions actually moved revenue versus which ones just moved margin.
I have also seen teams over-automate too fast. They set aggressive auto-approval thresholds before their matching model has learned enough from real data, then lose trust in the system when a batch of incorrect matches slips through. The fix is simple: start conservative, review exceptions manually for the first 60 days, and let the model earn its autonomy. Autonomous AI agents are genuinely powerful, but they need a human-in-the-loop process during the learning phase or you end up with confident errors instead of confident matches.
The future of this space points toward fully agentic analytics, where AI systems not only detect anomalies but explain them, prioritize them, and suggest corrective actions without waiting for a human to ask. That future is closer than most teams realize. The teams positioned to benefit are the ones who have already built clean, normalized, semantically consistent data pipelines today.
— Mateusz
Put your transaction data to work with Affinsy
Clean, automated transaction data is only valuable if you analyze it for the right patterns. Affinsy takes the normalized transaction records your pipeline produces and runs market basket analysis and RFM customer segmentation on them automatically, surfacing the product associations and customer behavior patterns that drive real revenue decisions.
You can connect via API, CSV upload, or MCP, so there is no complex integration required. Export your order data from Shopify, WooCommerce, BigCommerce, Stripe, or any platform that produces transactional data and feed it directly into Affinsy. The permanent free tier covers up to 20,000 line items with full product access and no credit card required. For teams ready to go further, Pro starts at $49 per month. Start turning your transaction data into growth decisions today at Affinsy.
FAQ
What is automated transaction analytics?
Automated transaction analytics is the use of software pipelines to ingest, normalize, match, and analyze transaction records with minimal manual input. It replaces spreadsheet-based reconciliation with AI-powered workflows that run continuously.
How long does it take to implement transaction automation?
Most teams complete a basic pipeline in 4–8 weeks, with the first 30–60 days focused on threshold tuning and normalization rule refinement. Full automation rates above 90% typically require 60–90 days of model learning.
Which payment processors can be automated?
Stripe, PayPal, Square, and ACH transfers all support API-based ingestion into automated analytics pipelines. Any processor that exports structured transaction data via API or CSV can be included in a multi-source workflow.
What is a semantic layer and why does it matter?
A semantic layer is a centralized definition of business metrics and logic that all reporting tools draw from. It prevents different teams from calculating the same KPI differently, which is the most common cause of conflicting reports in automated analytics systems.
How does AI improve matching accuracy over time?
Pattern-learning AI agents update their matching rules based on historical corrections made by human reviewers. This means automation rates increase the longer the system runs, as the model learns from every exception that gets resolved.
Recommended
- Transaction data analysis for e-commerce growth - Affinsy Blog | Affinsy
- Marketing analytics trends 2026: optimize ecommerce sales - Affinsy Blog | Affinsy
- Ecommerce Analytics Trends 2026: Unlocking Growth Through AI - Affinsy Blog | Affinsy
- Automation in analytics: driving e-commerce growth in 2026 - Affinsy Blog | Affinsy