
TL;DR:
- Historical data reveals demand patterns and customer behaviors that enable more accurate forecasting and smarter marketing strategies.
- Proper analysis requires clean, integrated, and validated data collected at high resolution, with ownership assigned for ongoing maintenance.
Historical data is the record of every transaction, customer interaction, and operational event your business has already experienced. Knowing why leverage historical data matters is the first question serious retail and e-commerce professionals ask when moving from gut-feel decisions to evidence-based strategy. Past data reveals demand cycles, buying patterns, and process failures that no real-time dashboard can reconstruct. Treated as a living asset rather than an archive, it becomes the foundation for accurate forecasting, smarter customer segmentation, and AI model training that actually works.
Why leverage historical data for retail and e-commerce decisions?
Historical data analysis is the practice of systematically examining past records to extract patterns that inform current and future business decisions. The benefits of historical data extend well beyond simple reporting. When you analyze order histories, return rates, and customer purchase sequences, you surface the kind of structural insight that shapes pricing, inventory, and marketing at the same time.

The most direct benefit is demand forecasting. Retailers who build forecasts from multi-year sales records account for seasonality, promotional lift, and product lifecycle effects that a 30-day rolling window misses entirely. A single missed seasonal spike can mean weeks of stockouts or, worse, months of excess inventory tying up working capital.
Customer behavior modeling built on historical purchase data reveals which products customers buy together, how long they take between orders, and when they are most likely to churn. These patterns are invisible in any single session but obvious across thousands of transactions. That is exactly the kind of signal that powers cross-sell recommendations and retention campaigns.
Key operational benefits of using historical data include:
- Reduced downtime. Organizations using dedicated data historians report measurable reductions in unplanned downtime because sub-second interval records make failure patterns traceable across months and years.
- Faster quality investigations. When a defect rate spikes, historical logs let teams pinpoint the exact shift, machine, or supplier batch responsible rather than guessing.
- Smarter resource allocation. Historical staffing and order volume data show which days and hours drive the most demand, so labor and logistics resources go where they are needed.
- Improved marketing ROI. Past campaign performance data shows which channels and offers drove repeat purchases, not just first conversions.
Pro Tip: Export at least 24 months of order data before running any demand forecast. Twelve months captures one seasonal cycle. Twenty-four months shows whether that cycle is consistent or shifting.
How can historical data improve strategic decisions and competitive intelligence?

Historical data does more than explain the past. It creates a competitive advantage by letting you anticipate what comes next. Historical data acts as a living knowledge base that embeds institutional knowledge alongside performance trends and metadata. That means new analysts can learn from years of context rather than starting from zero.
Product development benefits directly from this. When you track which product categories grew fastest over a three-year window, you can allocate development resources toward categories with proven momentum rather than chasing trends that look exciting in a single quarter.
Competitive intelligence works the same way. Historical pricing data, promotional calendars, and category performance trends reveal the rhythms competitors follow. Teams that track these patterns can time their own promotions to capture demand before or after competitor peaks rather than competing head-on.
“Embedding historical data into decision workflows transforms analytics from a reporting function into a strategic capability. The organizations that do this consistently outpace those that treat data as a post-hoc audit tool.” — Affinsy
Top product and engineering teams use historical usage data to find content half-lives and retention dips to time new feature launches or refactors. The same logic applies in retail: historical repurchase intervals tell you exactly when to send a reorder reminder, not when your email calendar says to.
Additional strategic uses of historical data include:
- Identifying which customer segments generate the highest lifetime value over 12 or 24 months, not just the highest first-order revenue
- Tracking how average order value shifts across seasons to inform bundle pricing decisions
- Spotting category cannibalization before it erodes margin, by comparing category growth rates over time
What challenges arise when using historical data?
The importance of historical data is clear, but extracting reliable insight from it is harder than most teams expect. Data quality is the first obstacle. Data quality issues, like 40% unusable timestamps, often surface only during analysis, increasing cleaning time beyond available resources. That figure is not a worst-case scenario. It is a common reality in raw operational logs.
Siloed data compounds the problem. When your order management system, customer support platform, and marketing automation tool each store data separately, correlations between them stay hidden. Linking these systems is what turns individual records into cross-functional insight.
- Define a focused analysis question before pulling data. A structured analysis question and roughly two hours of focused work can uncover systematic patterns like recurring rejects by day of week. Without a clear question, analysts drown in volume.
- Validate timestamps and completeness before analysis. Build automated checks that flag missing values, duplicate records, and out-of-range timestamps before any model or report runs.
- Require sufficient data volume. Reliable process analysis requires 30–100 data points per characteristic for statistically significant insights. Analyzing aggregated averages masks patterns like limit drift and weekday-specific anomalies.
- Guard against overfitting. In-sample backtesting results do not predict live performance. Curve-fitting inflates in-sample metrics in a way that looks convincing but fails in production.
- Assign analytical ownership. Data that nobody is responsible for maintaining degrades. Appoint a team or individual to own data quality standards and refresh schedules.
Pro Tip: Run a data audit before any major forecasting project. Check for timestamp gaps, duplicate order IDs, and product SKU inconsistencies. An hour of auditing saves days of debugging bad model outputs.
How to use historical data for forecasting and AI training
Time series analysis is the most widely used method for demand forecasting in retail and e-commerce. It treats historical sales as a sequence of observations and identifies trend, seasonality, and noise components. When you separate those three elements, you can project forward with a confidence interval rather than a single point estimate.
Backtesting is the standard method for validating any forecasting model or trading strategy against historical records. Backtesting strategies against 200 or more trades provides statistical evidence of a genuine edge. Fewer observations produce results that are statistically indistinguishable from luck. The same threshold applies to product recommendation models: test against a large enough historical sample before deploying to live traffic.
AI and machine learning models depend on historical data for both training and validation. Well-structured historical datasets provide context and volume for AI, enabling recognition of long-term patterns that real-time signals alone cannot detect. A recommendation engine trained on six weeks of data will miss seasonal preferences. One trained on two years of data will catch them.
| Method | Best use case | Minimum data requirement |
|---|---|---|
| Time series analysis | Demand and revenue forecasting | 24+ months of sales records |
| Market basket analysis | Cross-sell and bundle optimization | Thousands of multi-item transactions |
| RFM segmentation | Customer retention and targeting | 12+ months of customer purchase history |
| Backtesting | Model and strategy validation | 200+ historical observations per variable |
Pattern recognition applied to sales data insights also improves personalization. When a model learns that customers who buy product A within 30 days also buy product B at a high rate, it can trigger a targeted offer at exactly the right moment. That is not a hypothesis. It is a pattern confirmed by thousands of past transactions.
Pro Tip: Split your historical dataset into training and holdout sets before building any model. Train on 80% of the data and validate on the remaining 20%. This prevents the model from memorizing your data instead of learning from it.
What are the best practices for integrating and analyzing historical data?
Building a reliable historical data infrastructure is not a one-time project. It requires continuous collection, cross-system integration, and clear ownership. The following practices separate teams that extract real value from those that accumulate data without using it.
- Collect at the highest resolution your systems support. High-frequency data can always be aggregated later. Aggregated data can never be disaggregated. Sub-second operational logs, for example, enable root-cause analysis that daily summaries cannot.
- Break data silos by integrating across systems. Failure to link systems like order management, CRM, and marketing platforms hides the correlations that matter most. Cross-system integration is what lets you connect a customer’s support ticket history to their purchase frequency and churn risk.
- Centralize storage in a data warehouse or historian. Centralized storage makes historical records accessible to analysts, data scientists, and business stakeholders without requiring them to pull from multiple source systems.
- Set a recurring analysis cadence. Historical data analysis should not happen only when something goes wrong. Monthly or quarterly reviews of data-driven decision making keep teams ahead of emerging trends rather than reacting to them.
- Document data definitions and transformations. When a metric changes definition, historical comparisons break. Maintaining a data dictionary prevents silent inconsistencies from corrupting trend analysis.
- Make data accessible to decision-makers. Analysts should not be the only people who can query historical records. Self-service dashboards and pre-built reports put historical context in front of the people who act on it.
Key takeaways
Historical data is the single most reliable input for demand forecasting, customer segmentation, and AI model training in retail and e-commerce.
| Point | Details |
|---|---|
| Forecasting accuracy | Build forecasts from at least 24 months of sales records to capture full seasonal cycles. |
| Data quality first | Up to 40% of raw timestamps may be unusable; audit data before any analysis begins. |
| AI training depth | Well-structured historical datasets let AI models recognize long-term patterns that real-time signals miss. |
| Backtesting threshold | Validate models against 200 or more historical observations to achieve statistical confidence. |
| Cross-system integration | Linking order, CRM, and marketing data breaks silos and surfaces correlations that drive real decisions. |
What I’ve learned from watching teams ignore their own data
Most e-commerce teams I have worked with are not short on data. They are short on the habit of looking at it systematically. The most common mistake I see is treating historical records as a compliance archive rather than a decision tool. The data sits in a warehouse, the team runs on instinct, and the gap between what they know and what they act on keeps widening.
The second mistake is expecting historical data to be clean. It never is. The teams that get real value from their data are the ones that build cleaning and validation into their workflow from the start, not the ones that wait for a perfect dataset that never arrives.
What surprises most professionals is how quickly the value compounds. The first year of systematic historical analysis usually surfaces a handful of useful patterns. By year three, those patterns have been validated, refined, and embedded into forecasting models, segmentation logic, and product decisions. The organization stops reacting and starts anticipating. That shift is not dramatic. It is gradual, and it is permanent.
The teams that get there fastest are the ones that assign ownership early, ask focused questions, and resist the temptation to analyze everything at once. Historical data rewards discipline more than it rewards ambition.
— Mateusz
Affinsy turns your transaction history into decisions
Every order your store has ever processed contains patterns you have not seen yet. Affinsy analyzes that historical transaction data to surface product affinities through market basket analysis and segment your customers by recency, frequency, and monetary value through RFM-based customer segmentation. No data science background required.
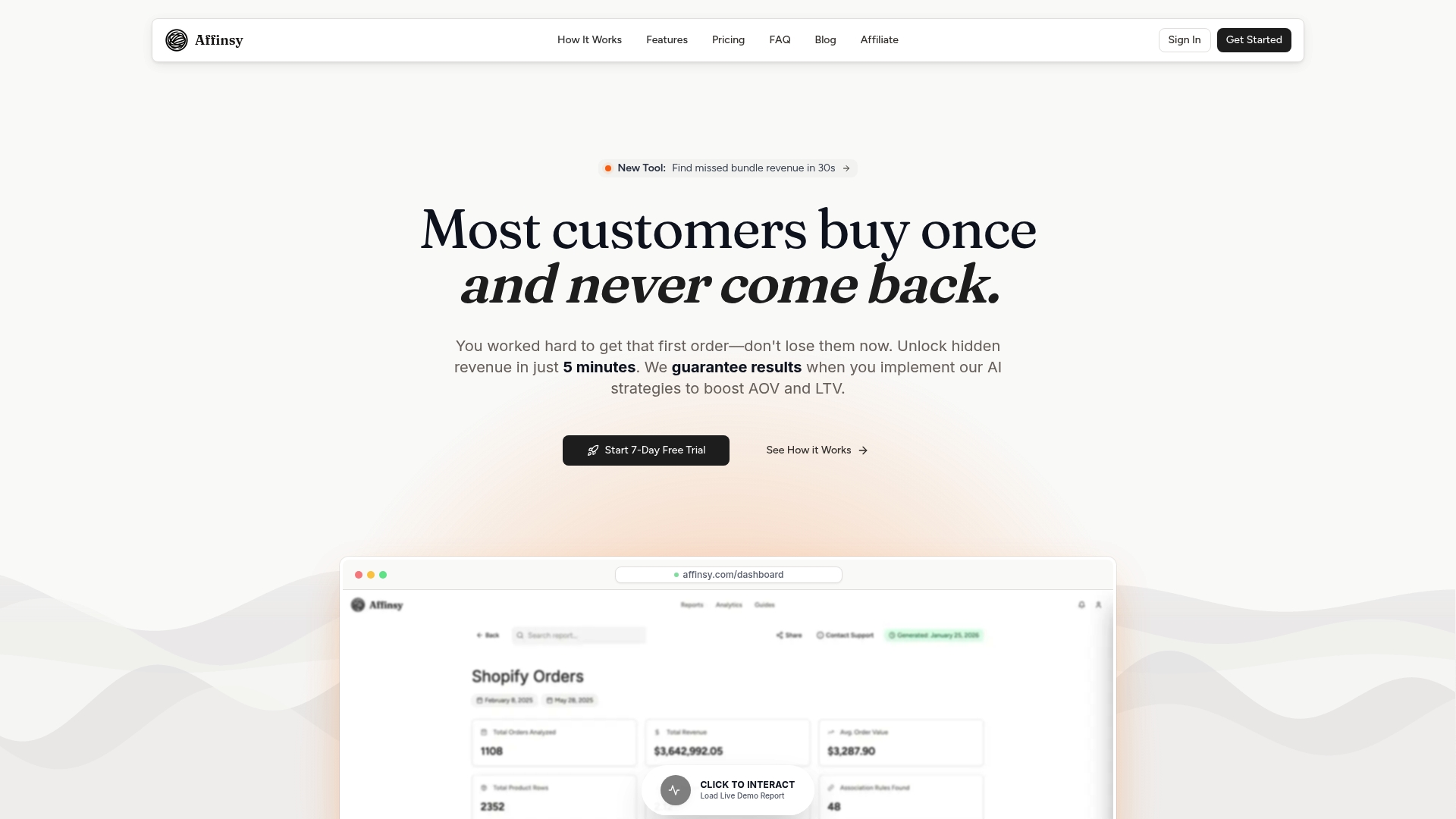
You export your order data from Shopify, WooCommerce, BigCommerce, Stripe, or any platform that produces transactional records, then upload via CSV or connect through the API. Affinsy’s permanent free tier covers up to 20,000 line items with full product access and no credit card required. Pro plans start at $49 per month for larger datasets. The patterns your historical data holds are already there. Affinsy makes them visible.
FAQ
Why does historical data matter for e-commerce forecasting?
Historical data captures seasonal cycles, promotional effects, and demand trends that real-time data cannot reconstruct. Forecasts built on multi-year records are structurally more accurate than those built on recent windows alone.
How much historical data do you need for reliable analysis?
Reliable process analysis requires 30–100 data points per characteristic for statistically significant results. For demand forecasting, at least 24 months of sales history covers one full seasonal cycle.
What is the biggest risk when using historical data for AI training?
Overfitting is the primary risk. In-sample backtesting results do not predict live performance, and models trained on too narrow a dataset memorize noise rather than learning real patterns.
How do you fix data quality problems in historical records?
Audit timestamps, remove duplicates, and validate completeness before any analysis begins. Automated validation routines catch the most common issues, including the roughly 40% of raw timestamps that are often unusable in operational logs.
What is market basket analysis and how does it use historical data?
Market basket analysis identifies which products customers buy together by analyzing past transaction records. It turns order history into cross-sell and bundle recommendations grounded in actual purchase behavior rather than assumptions.
Recommended
- Why Leverage Existing Data: A Guide for E-Commerce Teams - Affinsy Blog | Affinsy
- Sales Data Analysis: Unlocking E-Commerce Growth - Affinsy Blog | Affinsy
- Sales Data Insights: Powering E-Commerce Growth - Affinsy Blog | Affinsy
- Data-Driven Ecommerce Strategies for Smarter Growth - Affinsy Blog | Affinsy